
S.M.A.R.T. How to – Step by step guide for the disks health monitoring

If you’re running a server, the health and reliability of your storage infrastructure are two of your key concerns. Drive failures can lead to costly downtime, data loss, and reduced performance, especially in an environment where uptime means everything. S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) is an advanced technology built to proactively monitor your disks’ health, enabling early detection of impending issues before they become critical.
In this post, we will explore how you can implement and utilize S.M.A.R.T. monitoring to ensure the reliability and longevity of your disks, regardless of your underlying environment.
Step 1: Understand S.M.A.R.T. Monitoring
S.M.A.R.T. is a self-monitoring facility available on almost all modern hard disks and SSDs. It monitors various attributes related to disk performance and reliability. By tracking attributes like reallocated sectors, power-on hours, and temperature, the technology provides early warnings for imminent disk failures.
In setups, where the reliability of storage directly impacts the availability and integrity of hosted services, monitoring these attributes is critical.
Step 2: Set Up S.M.A.R.T. on Windows
If you are running on Windows, there are a couple of different ways to implement S.M.A.R.T. monitoring, depending on whether your disks are connected via a HW RAID controller/Fake Raid(Raid on Chip) or standalone.
RAID Configurations
MegaRAID Storage Manager (MSM) is developed by Broadcom (formerly LSI) and is designed specifically for managing and monitoring RAID controllers based on their chipsets. For monitoring RAID controllers from other manufacturers, you need to use software developed for those specific cards.
It’s worth noting that 99% of IPTP controllers are Broadcom (LSI). However, there are other manufacturers like Adaptec, which use entirely different systems. We have a few of these in our infrastructure as well.
While MSM provides a GUI-based approach for monitoring disks in RAID arrays, for more in-depth analysis, we still use smartctl (part of smartmontools) for disks behind the controller. Here’s how to use smartctl with RAID setups:
Standalone Disks
You can access S.M.A.R.T. information using smartmontools via the command line. Once installed, run the following command to get a full health report for the chosen drive:
smartctl -A /dev/sda
This command will enumerate key S.M.A.R.T. attributes, such as Reallocated Sector Count, Temperature, and Power-On Hours.
Scheduling with Automation on Windows
For Windows users who prefer automation, you can schedule tasks using PowerShell scripts or batch files to perform S.M.A.R.T. checks, create logs, or generate alerts when necessary.
Step 3: Set Up S.M.A.R.T. on Linux
For Linux systems running in headless mode in your serverCode, the process is a bit different. Most Linux distributions don’t include smartmontools by default, and even if installed, the S.M.A.R.T. service (smartd) may not be enabled out of the box.
Install smartmontools:
Install smartmontools using your distribution’s package manager:
- For Ubuntu/Debian:
sudo apt install smartmontools
- For RedHat/CentOS:
sudo yum install smartmontools
Enable the smartd daemon to monitor continuously:
sudo systemctl enable smartd
sudo systemctl start smartd
Change it’s configuration file –
sudo nano /etc/smartd.conf
Example config –
DEVICESCAN -a -o on -S on -n standby,q -s (S//./02|L//6/03) -W 4,35,40 -m root
Let’s break down this configuration:
- DEVICESCAN: Tells smartd to scan for all devices
- -a: Monitors all attributes
- -o on: Enables automatic offline testing
- -S on: Enables attribute autosave
- -n standby,q: Don’t check if disk is in standby, and be quiet about it
- -s (S//./02|L//6/03): Schedule short self-tests daily at 2am, and long self-tests weekly on Saturdays at 3am
- -W 4,35,40: Sets temperature thresholds (low, high, critical)
- -m root: Send email alerts to root user
To perform a quick health check of any disk, run:
sudo smartctl -A /dev/sda
This command will return a list of attributes, including Current Pending Sector Count, CRC Error Count, and Temperature, providing a general picture of the drive’s current health.
To gather all possible S.M.A.R.T. data from a disk, including health, use the following commands:
smartctl -h # Prints the help menu
smartctl --scan # Scans for all disks
smartctl -i /dev/sda # Displays information about a disk
smartctl -H /dev/sda # Performs a fast health check
smartctl -A /dev/sda # Displays all available information for the disk
For RAID setups, where the RAID controller might hide the actual physical disk information, the –scan command will reveal the correct path to each disk. An example output from a RAID environment:
smartctl --scan
/dev/bus/6 -d megaraid,12 # Disk 12 in the RAID array, SCSI device
/dev/bus/6 -d megaraid,13 # Disk 13 in the RAID array, SCSI device
Once you know the correct disk path, get detailed information with:
smartctl -A /dev/bus/6 -d megaraid,12
Automating on Linux
You can set up a cron job to automate this disk check and email you if any concerning attributes are found.
Step 4: S.M.A.R.T. Monitoring on RAID Systems
Monitoring individual disk health in RAID environments can be challenging because RAID controllers often obscure the details of each drive from the operating system. However, solutions exist for both Windows and Linux.
For Windows RAID Setups
MegaRAID Storage Manager is essential for S.M.A.R.T. monitoring in hardware RAID systems. It provides deep insight into the health of each disk in your RAID array, ensuring that failing drives don’t go unnoticed.
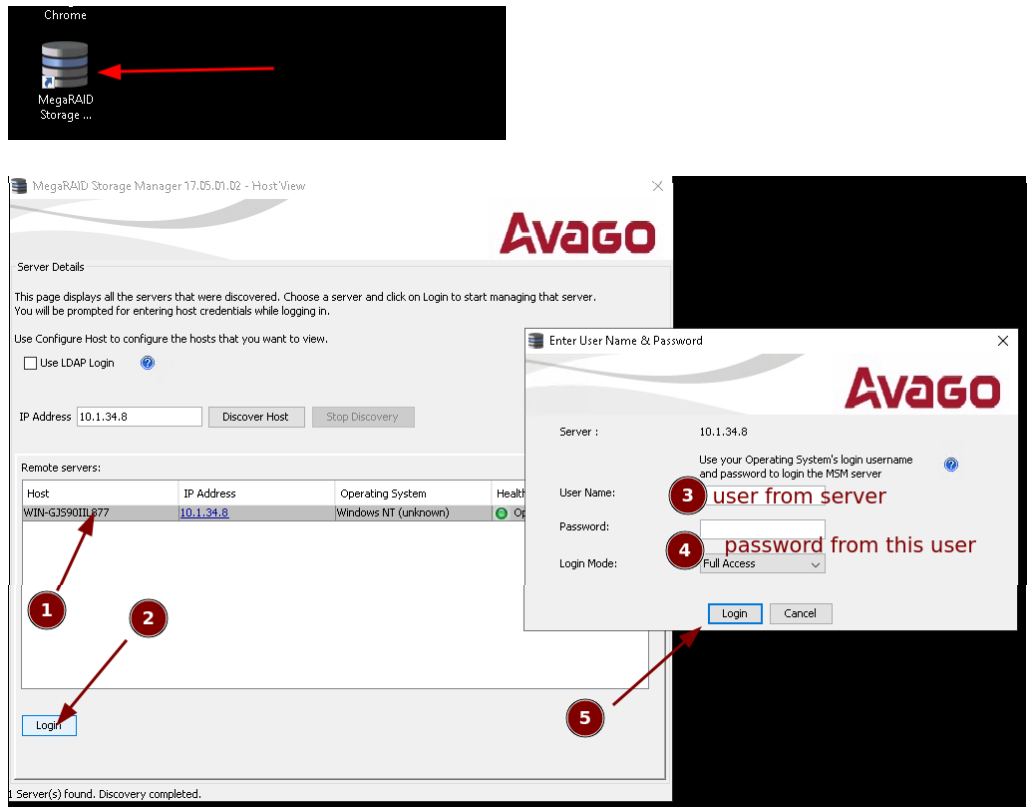
- Open MegaRAID Storage Manager, log in by entering the IP address, discover the host, select the server, and input the required username and password for full access.
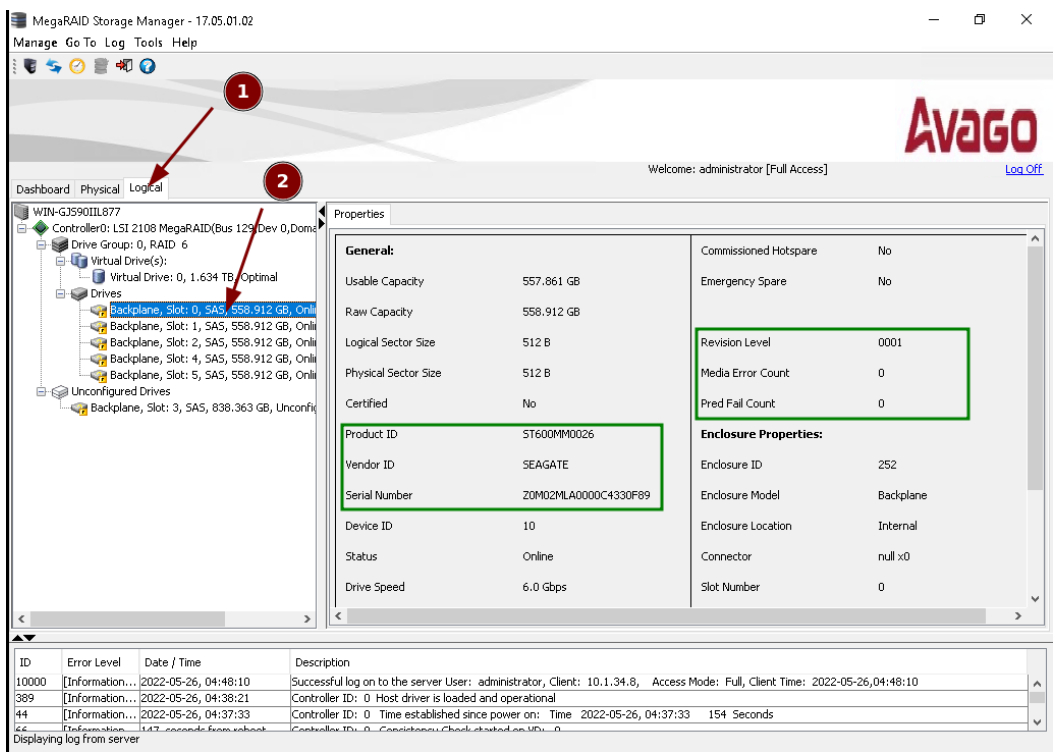
- Navigate to the “Logical” tab to view and select drives, and review key drive information like Product ID, Vendor ID, and critical S.M.A.R.T. metrics such as Media Error Count and Pred Fail Count.
For Linux RAID Setups
To manage and retrieve S.M.A.R.T. information from RAID arrays, use storcli:
sudo storcli /c0/e32/s0 show
This command allows you to pull the same S.M.A.R.T. metrics as standalone drives, keeping you informed about potential disk failures even in complex RAID configurations.
Step 5: What to Look For in S.M.A.R.T. Metrics
Not all S.M.A.R.T. attributes are equally important. Here are a few critical metrics you should focus on:
- Reallocated Sector Count: An increasing number of reallocated sectors suggests the drive is remapping bad sectors, which may indicate early failure.
- Temperature: Excessive heat can lead to premature drive failure. Ensure that your disks are operating within safe temperature ranges.
- Power-On Hours: This metric helps estimate the end-of-life of a drive by tracking how long it has been in use.
- Command Timeout & CRC Errors: These errors may signal communication issues between the drive and the controller, often due to hardware faults or signal interference.
- For Storage Devices: Watch the Media Wearout Indicator to monitor how close the device is to reaching its maximum number of read/write cycles.
Use hdparm for SSDs:
sudo hdparm --security-erase 12345 /dev/sdX
You can also use the dd command to overwrite data:
sudo dd if=/dev/zero of=/dev/sdX bs=4096 status=progress
This process ensures no private data remains on the disk, making it ready for reuse or retirement.
Conclusion: Proactive Health Monitoring for Storage Devices
S.M.A.R.T. monitoring is a highly effective tool for ensuring the long-term health and reliability of your storage. By regularly checking critical S.M.A.R.T. metrics, automating checks, and understanding the signs of potential failure, you can avoid unexpected downtime and extend your hardware’s lifespan.
For uptime-critical server environments, where data integrity is most important, S.M.A.R.T. monitoring ensures you’re always one step ahead of hardware issues. Whether you’re running Windows or Linux, or managing complex RAID arrays, this guide provides the steps needed to ensure your infrastructure stays healthy and secure.
Ready to implement S.M.A.R.T. monitoring in your server? With the right tools and automation, you can ensure your infrastructure remains reliable and secure.
